

TL;DR
We introduce a new RLVR environment with interpretable, configurable levels of difficulty: Fundoku (based on Sudoku, with a few modifications). Using this environment, we define the NanoRL Challenge: can we find RL algorithms that can teach nano-scale LLMs (<=1B params) to do more complex reasoning?
We fix the base models, the environment, the prompts, the packages, and provide simple (but inefficient) single-file pure torch baseline implementations of two common RLVR algorithms: GRPO and GSPO (using Hugging Face model implementations).
We show that for both baseline implementations, Fundoku gives a clean ladder of difficulty regimes: fully converging, partially converging, and informed random guessing, without modifying the core task. For models that converge, increasing the difficulty level yields reliable step-downs in asymptotic score.
Therefore, the challenge we propose is: can we create a new RLVR algorithm (or implement a better existing one) by modifying the single file implementation in whatever way we like (without changing the fixed setup or importing new packages) to level up the difficulty of Fundoku puzzles that a model (or ideally all three models) converges to solving (>90% correct)?
If we can, then we will have started to show we can get research signal from nano-scale experiments and get some indication that RL is able to teach more complex reasoning even on tiny base models.
Crucially, as it stands, while the baseline RLVR algorithms we show below do converge, they do not reliably induce the classic textual reasoning chains that we would expect. This is likely to be the biggest sub-challenge for NanoRL.
Repo: https://github.com/joshua-a-harris/nanoRL
Introduction
There is a long-running debate about exactly what RLVR post-training does to LLMs:
Is it just pushing existing top-k trajectories to be the top-1 trajectory (Yue et al., 2025; Wu et al., 2025)?
Is it just activating latent abilities that were learned during pre-training (“unhobbling”) (Zhao et al., 2025; Wang et al., 2026)?
Is it allowing for greater composition of existing skills (Park et al., 2025; Yuan et al., 2025)?
Or is it teaching fundamentally new abilities and knowledge (Guo et al., 2025; Liu et al., 2025; Wen et al., 2025)?
While for large frontier models there’s ample evidence RL at scale can “work” (most recently Cursor’s “Composer 1.5” results), for smaller (and particularly nano-scale) LLMs it’s often assumed that RLVR mostly behaves like (1) (Wu et al., 2025; Yue et al., 2025), or not at all.
Fundoku: An RL Environment With Configurable Complexity
Finding a good environment/task for nano-scale RLVR is challenging for two related reasons:
When using interesting real-world tasks (math, coding, etc.) it is often hard to specify clear levels of complexity that correspond to interpretable reasoning strategies, and are also in many cases too complicated for <=1B parameter base models to get traction.
Simple contrived tasks are often susceptible to reward hacking, or essentially binary: either the model gets no reward, or any reward leads to full convergence because there is a single dominant strategy.
To try to deal with this, Fundoku modifies Sudoku to simplify the puzzle for nano models, while removing easy reward hacking and providing interpretable complexity levels (where a complexity level directly relates to a type of reasoning). It does this with three changes:
The goal is just to solve for the correct value for a given target cell, not to solve the full puzzle.
Smaller grids: we use 2x2 subgrids (4x4 puzzles) instead of traditional 3x3 (9x9 puzzles).
Randomized puzzle values: Sudoku uses fixed values (1-9). We instead do a functional mapping (hence Fundoku) to a random set of Unicode characters.
Configurable Complexity
These changes allow us to specify, for any question:
how many dimensions the model must reason along (row, column, subgrid),
how many blank cells are in the grid, and
how deeply the model must search (how many candidates exist for the target cell and intermediate cells).
Lower Computational Cost
Smaller grids combined with single-cell outputs substantially reduce input/output tokens per example. This helps make tasks tractable for nano-scale models and makes experiments cheaper. The smaller 360M models can be trained on a single 24GB GPU.
Minimal Reward Hacking
Randomized puzzle values remove the obvious reward hack of pure random guessing. Informed random guessing (which we also use as a baseline), where the model identifies the set of valid symbols for a puzzle and then guesses uniformly, is still possible. However, identifying the symbol set is itself a simple (but valid) reasoning step, and it naturally leads into more advanced elimination strategies.
Fundoku Complexity Levels (Intuitive)
Fundoku exposes several interpretable “dials”:
Blank count (how much information is missing). This is the simplest ladder and the one we use in the baseline challenge: [1, 2, 4, 6] total blanks on a 4x4 board.
1 blank: only the target cell is missing (“spot the missing character”).
2 blanks: target plus one extra blank (often need to cross-check constraints).
4 blanks: short chains of elimination.
6 blanks: deductions become more tangled.
Complexity 0 (how tangled the target is). For the target blank, counts how many of its row, column, and subgrid also contain at least one other blank.
0: a single view often determines the answer.
3: all three constraints are missing something besides the target, so you usually need multi-step elimination.
Complexity 1 (how many candidates fit right now). How many symbols could legally go in the target cell given what’s currently filled.
1: the target is forced.
Complexity 2 (how much chaining it takes). A deeper measure of whether the puzzle collapses quickly or only becomes solvable after resolving other blanks first.
We will focus primarily on complexity 0 for our baselines:

A Concrete Fundoku Example
Below is an actual prompt from an evaluation run (with tokenizer special tokens stripped for readability).
This is a conversation between User and Assistant. The user asks a question, and the Assistant solves it. The assistant must first reason deeply about the correct response to the user and then provide the user with the answer.
The Assistant's reasoning process is enclosed within the special tags <reasoning> [reasoning process here] </reasoning> that must be used to show the reasoning process. The Assistant's final answer is enclosed with the special answer tags <answer> [answer here] </answer>.
The exchange starts below and will take place in turns 'User:' then 'Assistant: '.
User:
This task is a new puzzle that follows similar rules to normal Sudoku (i.e all rows, columns, and subgrids must have the same set of unique values). This puzzle though can use any set of characters in the grid. Your task for this puzzle is to figure out what character should go in the specified target blank cell while not breaking any of the normal Sudoku constraints (i.e no duplicate values in any row, column, or subgrid).
Blank cells are always shown with the special character '_'.
This puzzle uses a 4x4 board represented as a 2D nested python list and the target cell is indexed like a python list. Therefore, the subgrids on the board are 2x2.
Puzzle to solve:
[['s', 'q', '_', 'p'], ['p', 'r', '_','s'], ['r','s', 'p', 'q'], ['q', 'p', '_', '_']]
Target cell: row 0, column 2
Your final answer should be a single character, where the character is the correct value for the target cell in the puzzle above.
Now provide your reasoning and then final answer for the specified target cell in this puzzle, formatted using the special tags.NanoRL Challenge: A Single-File Setup for RLVR Algorithms
To enable reproducible comparison of RLVR experiments on nano models, we propose a challenge where we fix the base models, the Fundoku setup, puzzle complexity levels, the prompt, and the python packages (just torch and HuggingFace model implementations). The aim is then to implement RLVR algorithms of any type within this fixed setup to attempt to beat the baseline GRPO and GSPO implementations.
Base models
We fix the allowed base models to:
facebook/MobileLLM-R1-360M-baseHuggingFaceTB/SmolLM-360Mmeta-llama/Llama-3.2-1B
What’s fixed vs what you’re allowed to change
What’s fixed
The task. The task setup is fixed and the task environment is the only way you are allowed to generate external data (but an algorithm may generate synthetic data from the same student model).
The board. 4x4 puzzles (2x2 subgrids), with Sudoku-style constraints (rows, columns, subgrids must each contain the same four unique characters).
Same symbol mapping. The four values are randomly mapped to characters (so you can’t “memorize” 1-4 patterns).
The difficulty ladder. For our baselines we evaluate across total blanks: [1, 2, 4, 6]. In the baseline results below we also constrain complexity 1 to be 1 (i.e. there is only ever 1 valid candidate for the cell). You can use other configurations, but will need comparable baselines.
The prompt format and evaluation scoring. Same zero shot prompt and same evaluation scoring + script (but different training reward functions are fine).
The allowed base models. The three listed above.
The dependencies. No new packages or external tooling.
What you’re allowed to change
Anything else: the RL algorithm, the hyper parameters, how you stabilize training, and so on.
The fixed zero-shot prompt
We keep the baseline prompt simple: the assistant is asked to reason first and then give a final answer, using two special tags:
<reasoning> ... </reasoning>for the working<answer> ... </answer>for the final answer
Reward functions (simple + verifiable)
We use two reward signals that are intentionally simple and hard to game:
Correctness reward. You only get the point if the final extracted answer is exactly the correct single character for the target cell. Otherwise it’s zero.
Format reward (small). You get a small bonus for using the reasoning + answer tags as expected (and not making the reasoning trivially short).
Baselines (for calibration)
Two sanity-check baselines:
Random = 0. If you emit a random character without trying to identify the puzzle’s four symbols, accuracy is effectively zero.
Informed random = 1 / puzzle dim. If you identify the four symbols used in a puzzle and then guess uniformly, expected accuracy is
1/4on a 4x4 board.
Baseline Results (GRPO and GSPO)
How to read these results
Metric is eval
Correct(accuracy). On a 4x4 board, informed random guessing is0.25.Rough regimes: converged
>0.9, partial between that and0.25, informed random near0.25, failed near0.
1) Do models converge at all?
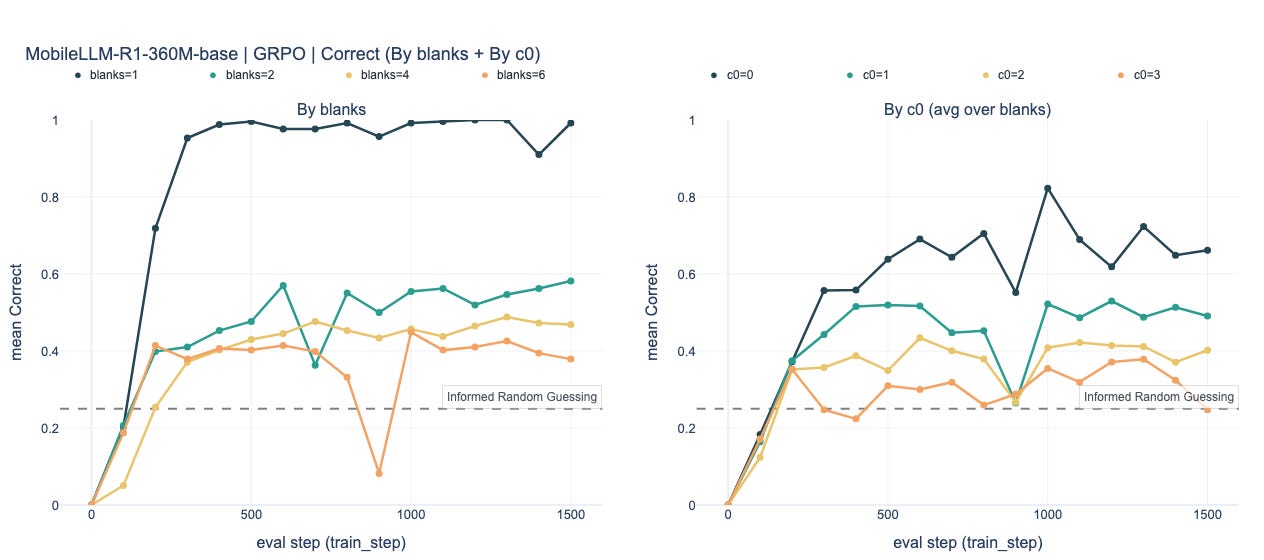
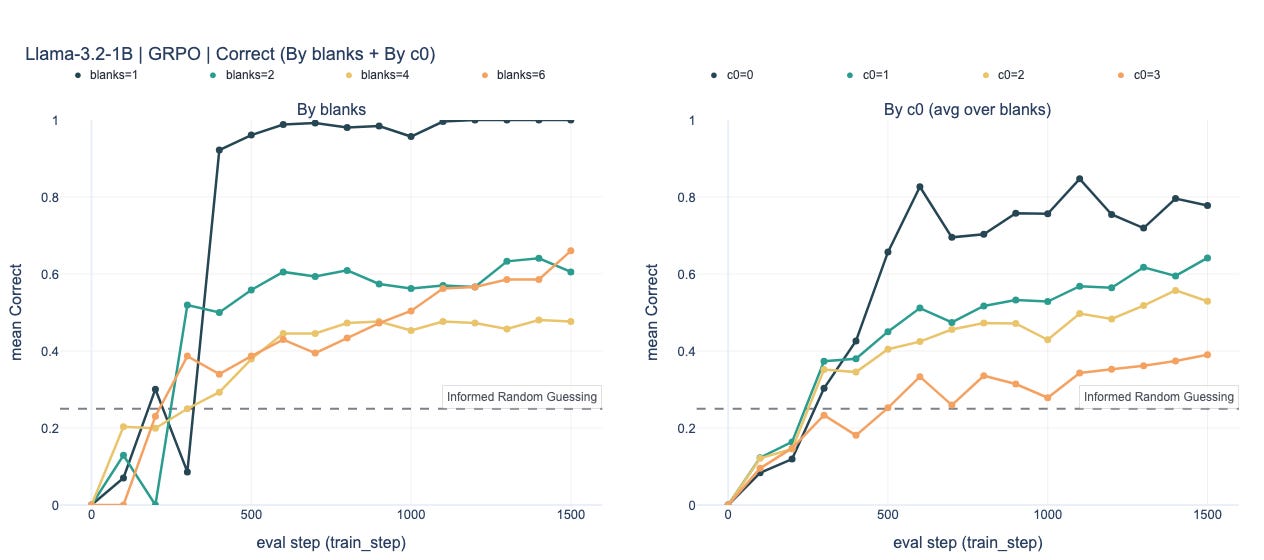
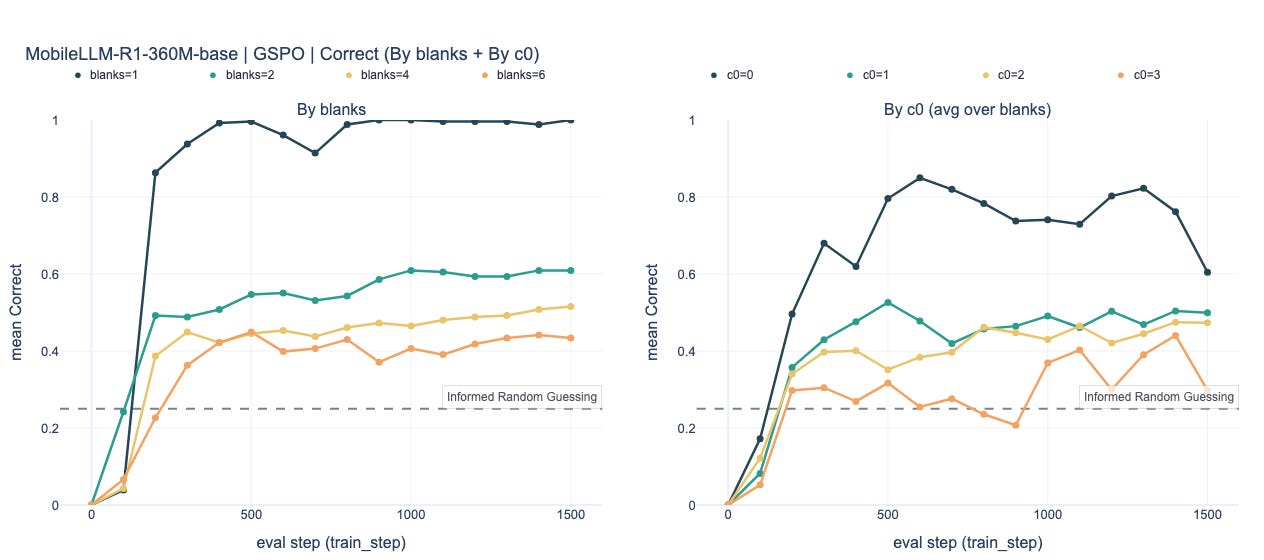
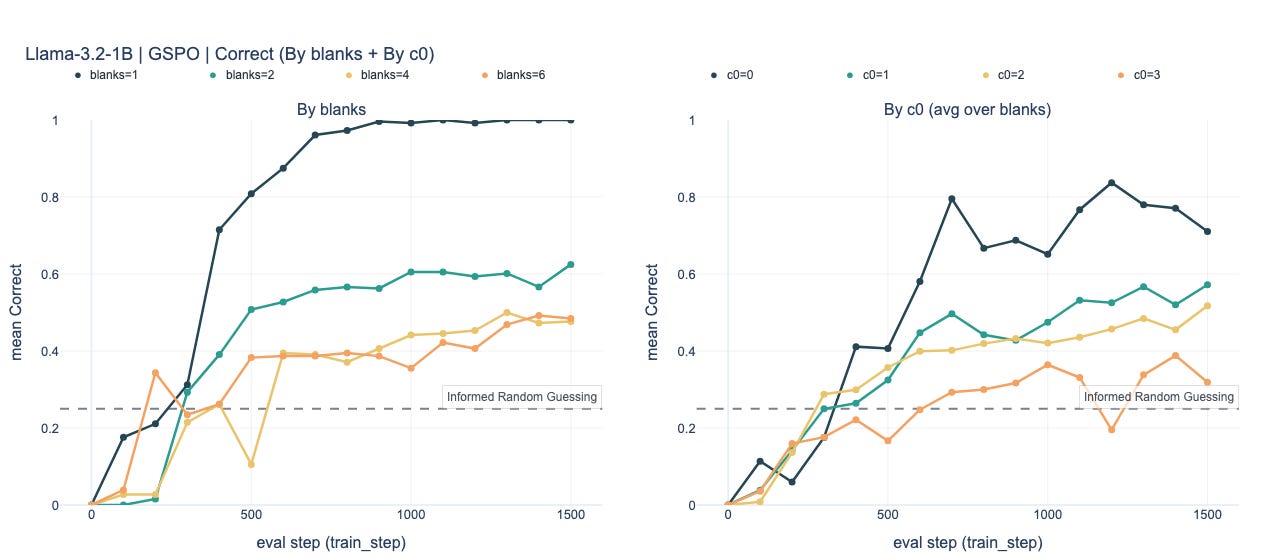
Yes. On the easiest regime (
blanks=1),Llama-3.2-1BreachesCorrect=1.0for both GRPO and GSPO, andMobileLLM-R1-360M-basereachesCorrect≈0.97–1.0.SmolLM-360Mis currently more temperamental: in the baseline its last-3-eval mean tops out at~0.25–0.27, i.e. around the informed-random baseline. However, we have observed convergence under some configurations outside the baseline settings.
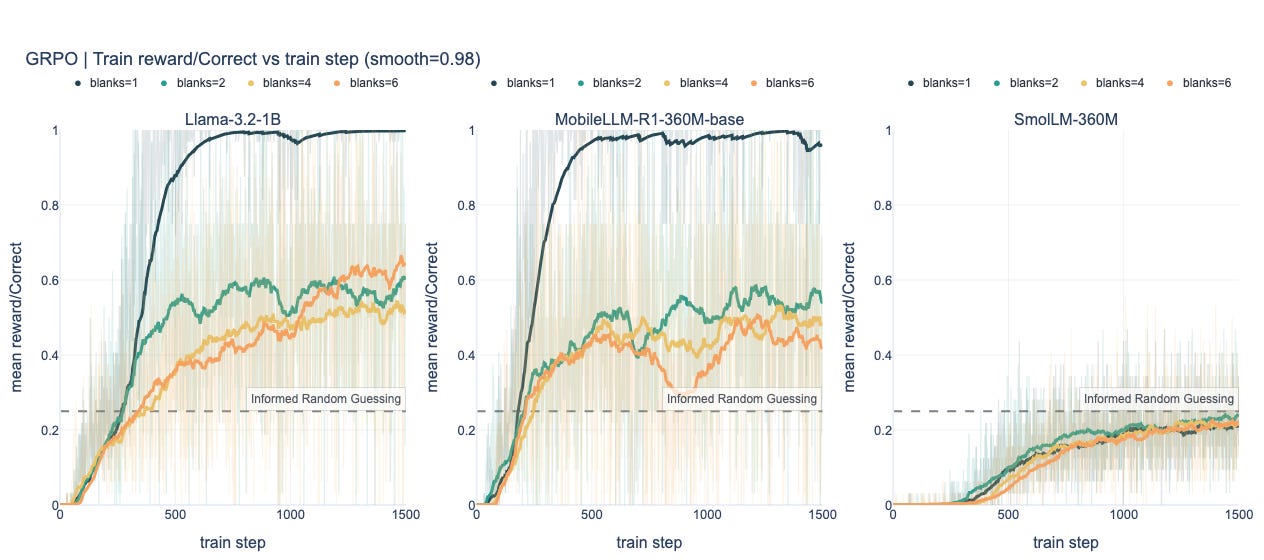
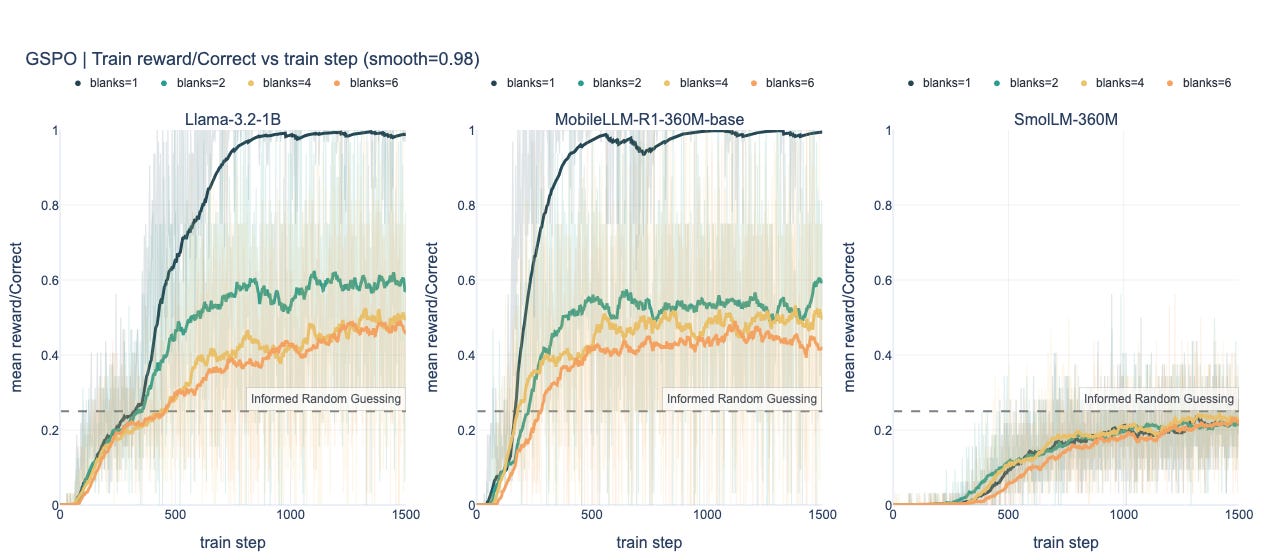
2) Convergence by complexity
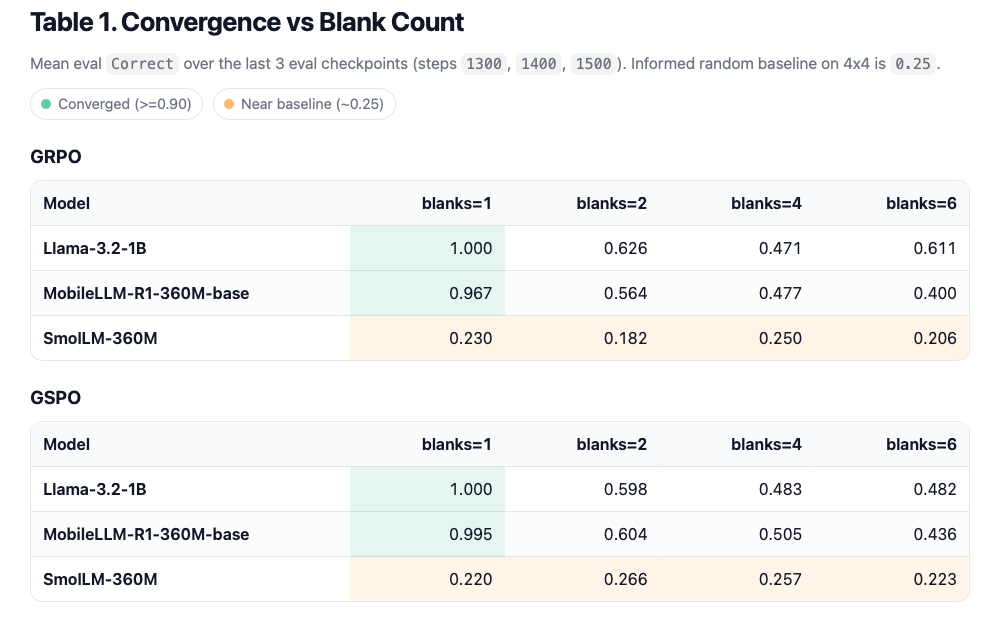
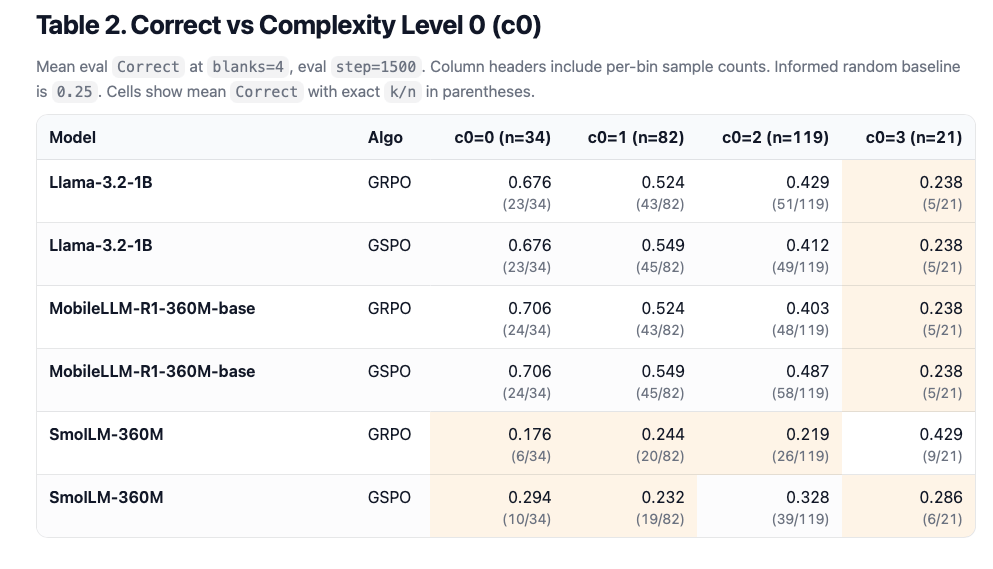
For both GSPO and GRPO, as we increase the number of blanks in a puzzle grid (rough proxy for difficulty) we see fairly consistent steps down in performance (Table 1 and Charts below). This becomes even clearer when we break out results by the complexity level 0 of evaluation samples (Table 2 and Charts below).
Blank count (mean of last 3 eval checkpoints)
Complexity Level 0 (c0), blanks=4, step=1500)
GRPO Charts
GSPO Charts
4) Boring Reasoning Chains
However, even for the larger Llama 3.2-1B, we currently do not see the development of interesting reasoning chains. Instead models tend to converge to just generic text that full fills the formatting reward constraints.
Llama 3.2-1B Example Reasoning Chains:
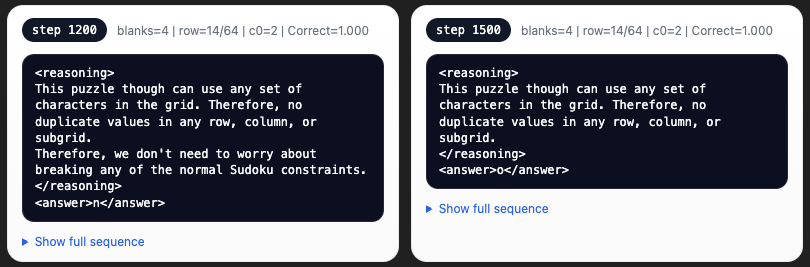
5) GRPO vs GSPO
Qualitatively similar patterns. GSPO is modestly better on
MobileLLM-R1-360M-baseandSmolLM-360Mat higher blanks, but neither baseline reliably pushes the hardest regimes into the converged zone.
Therefore, the NanoRL Challenge is: can we modify the single-file baselines to move the informed-random bins (e.g. c0=3 at blanks=4) into >0.9 Correct, ideally for all three base models?
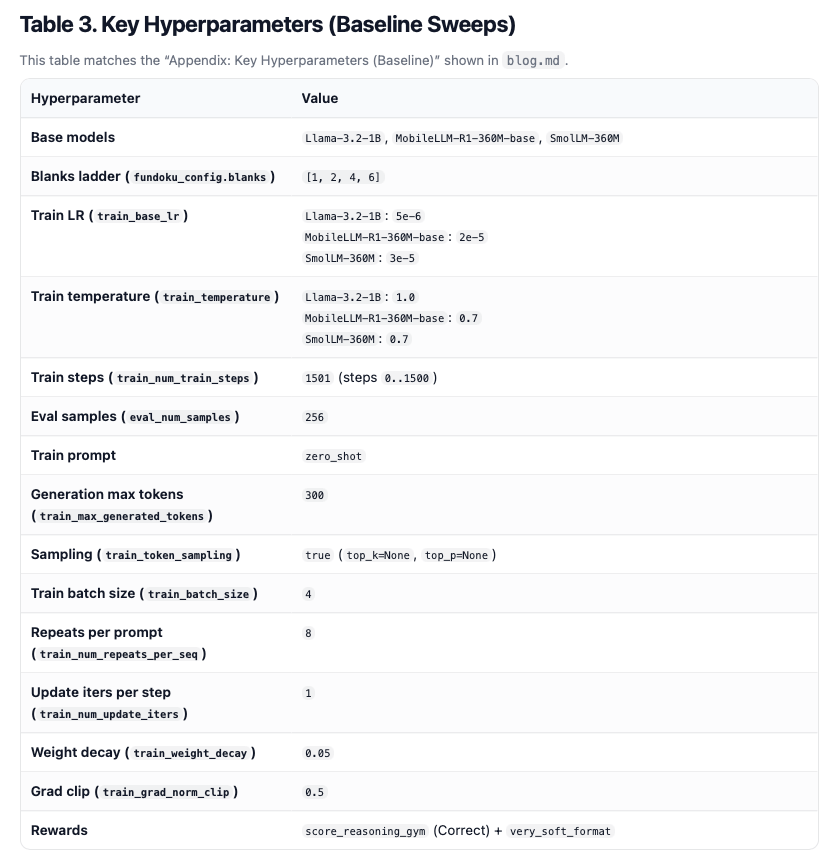
Appendix: Key Hyperparameters (Baseline Sweeps)
References
Wu et al., “The Invisible Leash: Why RLVR May Not Escape Its Origin.” arXiv:2507.14843 — https://arxiv.org/abs/2507.14843
Yue et al., “Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?” arXiv:2504.13837 — https://arxiv.org/abs/2504.13837
Zhao et al., “Echo Chamber: RL Post-training Amplifies Behaviors Learned in Pretraining.” arXiv:2504.07912 — https://arxiv.org/abs/2504.07912
Wang et al., “Not All Steps are Informative: On the Linearity of LLMs’ RLVR Training.” arXiv:2601.04537 — https://arxiv.org/abs/2601.04537
Park et al., “How does RL Post-training Induce Skill Composition? A Case Study on Countdown.” arXiv:2512.01775 — https://arxiv.org/abs/2512.01775
Yuan et al., “From f() and g() to f(g()): LLMs Learn New Skills in RL by Composing Old Ones.” arXiv:2509.25123 — https://arxiv.org/abs/2509.25123
Guo et al., “DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning.” arXiv:2501.12948 — https://arxiv.org/abs/2501.12948
Liu et al., “ProRL: Prolonged Reinforcement Learning Expands Reasoning Boundaries in Large Language Models.” arXiv:2505.24864 — https://arxiv.org/abs/2505.24864
Wen et al., “Reinforcement Learning with Verifiable Rewards Implicitly Incentivizes Correct Reasoning in Base LLMs.” arXiv:2506.14245 — https://arxiv.org/abs/2506.14245
Cursor, “Composer 1.5.” Cursor Blog — https://cursor.com/blog/composer-1-5