

This blog is written in a personal capacity and all opinions are my own.
This is the second in a series of posts summarising work I've helped publish at the UK Health Security Agency (UKHSA) assessing the potential of Large Language Models (LLMs) within public health. This blog focuses on recent work developing a benchmark to evaluate LLMs' knowledge of UK Government public health guidance.
Introduction
In LLMs in Public Health - Part 1, I discussed work evaluating LLMs' ability to support public health organisations with some of their core functions, such as disease surveillance and outbreak response. This post focuses on work understanding the broader implications of LLMs on how public health guidance is shared.
Guidance issued by public health institutions covers everything from who is eligible for certain vaccination programs to how to respond to an incident involving radioactive material. As a result, it represents a key source of information for residents and experts to inform personal, professional, and clinical decision making.
The rapid growth of chatbots (e.g ChatGPT) and other LLM applications could significantly change how this guidance is retrieved and disseminated. For example, instead of using a search engine to find the official documentation (on gov.uk), in the future some individuals may ask chatbots about UK guidance, or they may ask LLM-based applications for advice that relates to topics covered by official guidance (or even AI overviews embedded in search engines). The risk of ‘hallucinations’ (mistakes) by LLMs means these new options for querying public health information could have an impact on the public.
Furthermore, whilst LLMs are trained on a huge amount of text, very likely including UK Government guidance documents, there are a few reasons to think LLMs could be more vulnerable to hallucinations in this area:
Guidance changes - Current UK Government guidance has often been updated quite recently. In our case 31% of the documents used as source text had been at least partially updated in 2024. Hence, questions about current guidance may be less well represented in training datasets than other factual topics.
Numerous guidance versions globally - On any one public health topic many public health institutions in different countries around the world will have published online slightly different guidance with slightly different recommendations. This means there is an additional hallucination risk that LLMs respond with recommendations on the correct topic but from a different public health institution (e.g, the US CDC), which doesn’t exist for many other subjects that don’t vary by country (e.g, maths questions).
Niche topics - The breadth of public health means that some recommendations apply to situations that very rarely occur (e.g, the specific code for a specific chemical being spilled in a specific way in England). We expect these pieces of information to be relatively sparsely represented on the internet vs, for example, medical information that is repeated across numerous textbooks, medical exams, forums, academic papers etc.
Therefore, an important question for UK public health institutions is: how much knowledge of UK guidance do current LLMs possess and how often do they accurately respond to questions about topics covered by official documentation?
This blog digs into our first attempt to design, generate, and run evaluations to answer this question.
Results spoiler
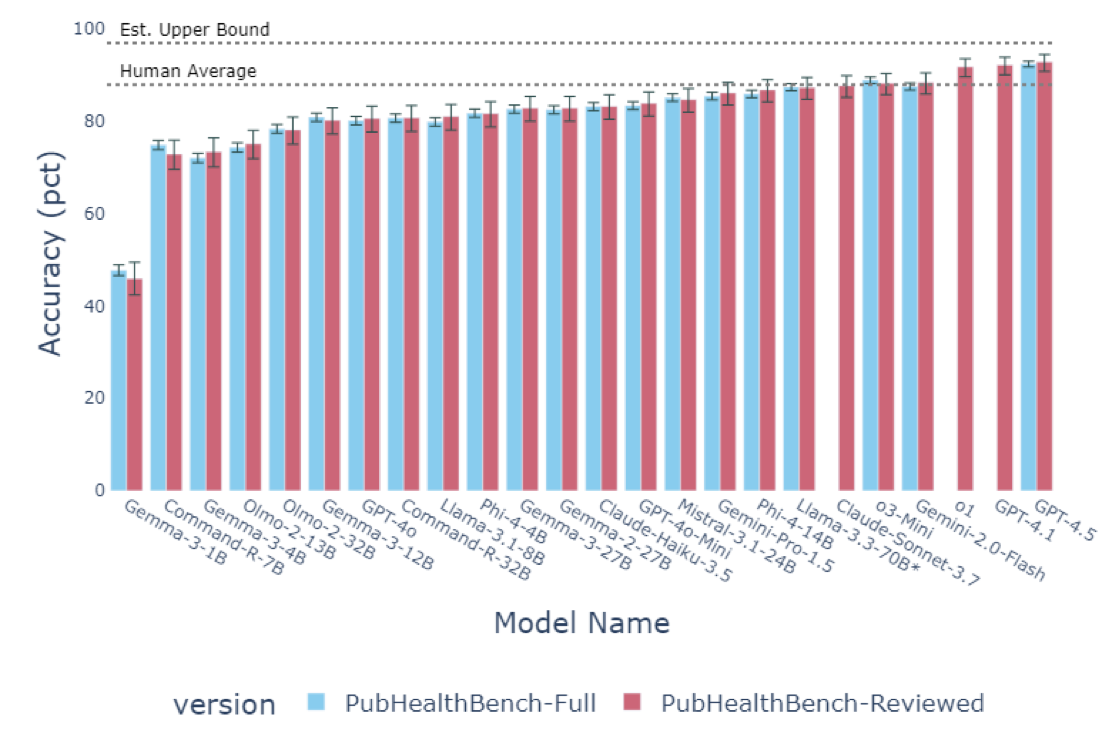
We find that, even without access to search tools, the latest LLMs know a lot about UK Government public health guidance and more than I personally expected given the above - When tested using multiple choice format questions in the hardest setting with no examples, no access to search tools, no chain of thought (unless a reasoning model) - the latest private models, as of April 2025 (GPT-4.5, GPT-4.1, o1), score over 90% and above what on average non-expert humans achieve with brief search engine use.
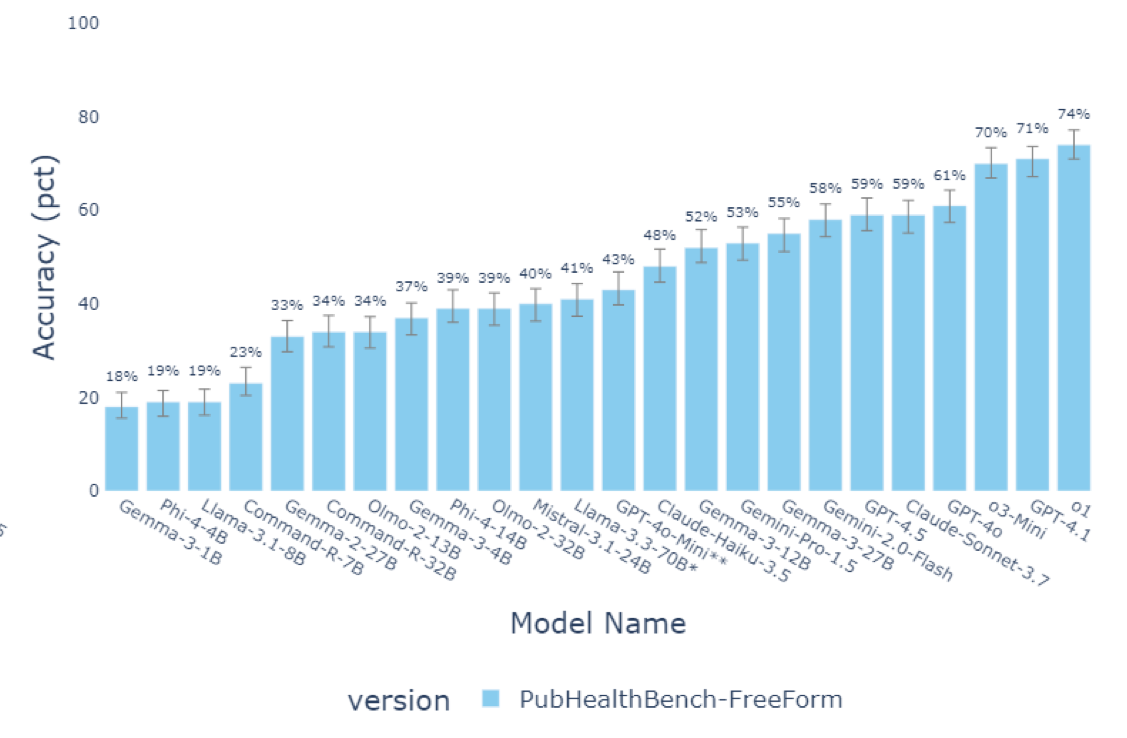
However, even the best current LLMs get a lot worse when they are asked to provide free text responses - When tested in the free form setting (not multiple choice), the highest performing LLM (o1) scored just under 75%. Therefore, hallucination risks could still be meaningful when used in a chatbot style setup (without search tools) - highlighting the continuing importance of developing robust automated free form response evaluations in this area.
For full details see our recent pre-print:
Healthy LLMs? Benchmarking LLM Knowledge of UK Government Public Health Information
Generating a public health benchmark
Before we go into the details on how we tested the LLMs, a few pieces of terminology.
Terminology
Test = Evaluation = Benchmark: Three ways of referring to a dataset that allows you to assess how good LLMs are at something, all mean basically the same thing for our purposes.
MCQA: Multiple Choice Question Answering - think school or university multiple choice exams.
Free Form = Unstructured = Free Text Response: Three ways of saying the text involved doesn't have a specified structure.
Chunk = Section = Part of Text: All ways of referring to a smaller part of the text from a larger document.
Step 1 - Developing a comprehensive test

The first problem we faced is that there aren't any existing comprehensive tests of UK government public health guidance. Public health guidance is also frequently revised and so any test also needs to be amenable to regular updates. So we decided to start from scratch with the official documents.
We used a 4 step pipeline:
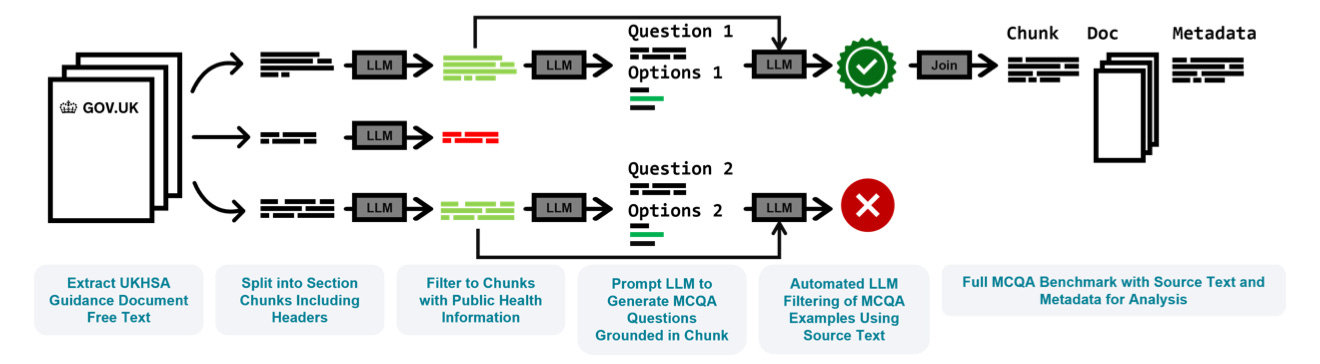
(1) Source Text - We collected, extracted, markdown formatted, and chunked the text from 687 publicly available documents on the UK Government website (gov.uk).
(2) Filtering - We then filtered and classified the over 20,000 sections of text to identify the parts containing relevant public health information.
(3) Question Generation - Each of the sections identified as relevant were then passed individually to an LLM (Llama-3.3 70B) to generate 2 multiple choice questions (see examples below).
(4) Automated Checks - Finally, the over 15,000 questions generated were then passed back to an LLM to check for consistency with the source text and question quality.
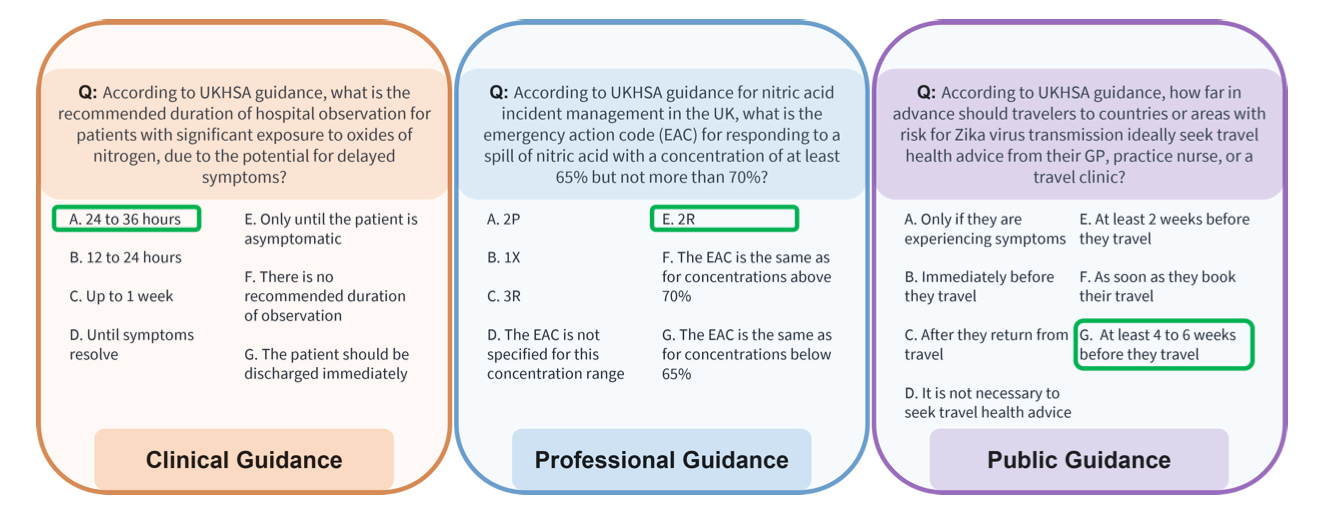
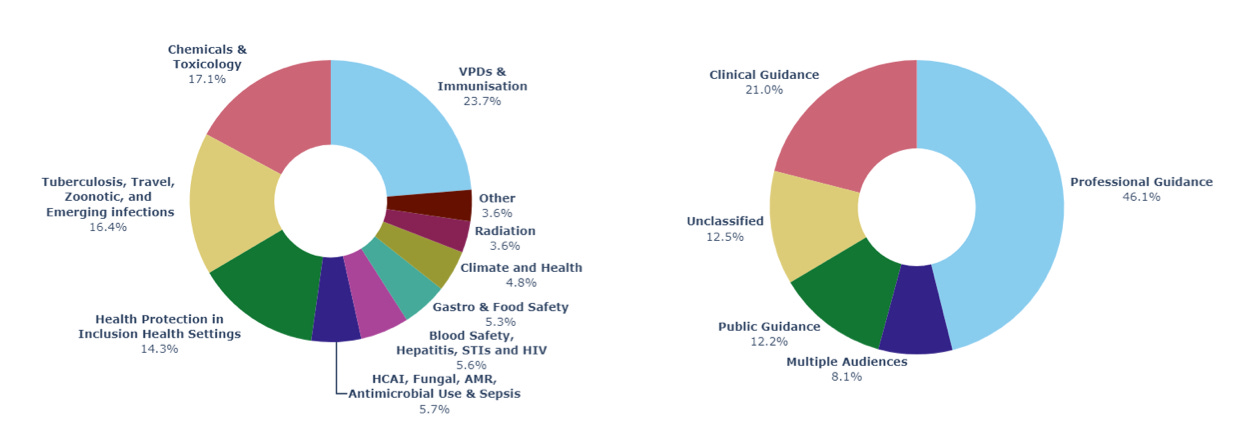
After rebalancing the dataset between topics, the final test has over 8,000 questions. These questions cover public, clinical, and professional guidance across 10 public health topic areas, and 352 guidance areas.
Step 2 - Estimating question error rates and human baseline

Error rate
Almost all large LLM evaluations (and many human ones) contain errors or ambiguity in the question set that mean achieving 100% isn't possible because some questions either cannot be answered reliably or the stated correct answer is actually incorrect. Given our questions were generated by an LLM a crucial step was understanding the rate of unanswerable questions in the dataset.
Therefore, human experts manually annotated 10% of the questions to assess whether they were answerable. Using a strict protocol defining question quality, we estimated a 5.5% error rate in the benchmark. However, given the main source of errors were examples where there existed another equally correct answer in the options list (and so the correct answer should still be a 50:50 guess), we estimate the maximum score possible to be approximately 97%.
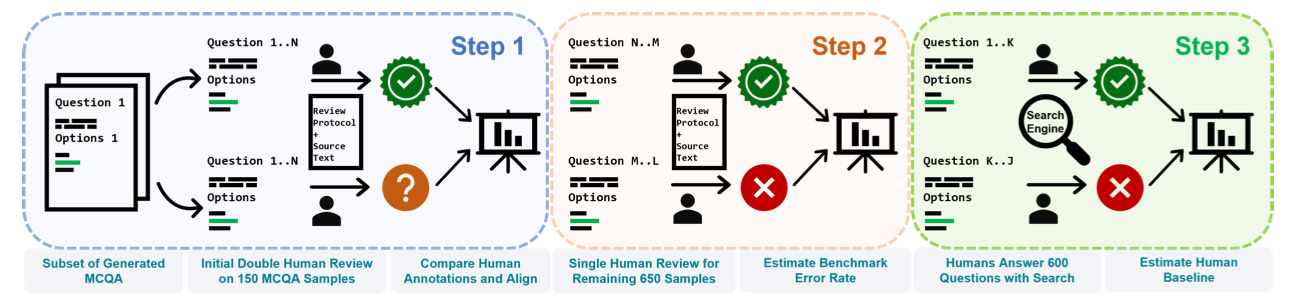
Human baseline
Given we are interested in the real world implications of current (and future) LLM capabilities, we specifically wanted to test whether an LLM was more or less likely to provide accurate answers than non-expert humans with cursory search engine use. To set this human baseline, we asked 5 humans to take 600 questions randomly drawn from the full benchmark dataset and allowed them access to search engines, but encouraged only brief use.
Under these conditions the humans scored on average 88% on the multiple choice questions, setting the threshold for where LLMs could potentially be more accurate than a cursory search.
Step 3 - Free form responses, LLMs assessing LLMs

Once we had our multiple choice test set-up, the remaining step was to be able to also evaluate LLMs’ free form responses (i.e how a chatbot would respond to a normal query in the real world).
This is a fundamental challenge of evaluating LLMs as they are very easy to test on tasks where you can check automatically if the answer the LLM gives is correct (e.g multiple choice exams), but incredibly hard to test on tasks where you have no way of checking accuracy without a human reading the answer (e.g writing an essay).
To get round this problem we leverage a big advantage of the way we constructed our benchmark - that every question can be traced back to the exact part of the source text and document it came from.
This enables us to use one increasingly popular way of solving this problem. We replace a human having to read the free form response to check its accuracy, with another LLM reading the free form response instead (i.e an LLM 'judge'). Our LLM judge is provided with the official source text (along with other relevant official guidance) and asked to decide whether the free form response given by the LLM being tested is consistent with the official guidance. By providing the exact source text the question came from, our LLM judge can much more reliably assess responses in an automated way.
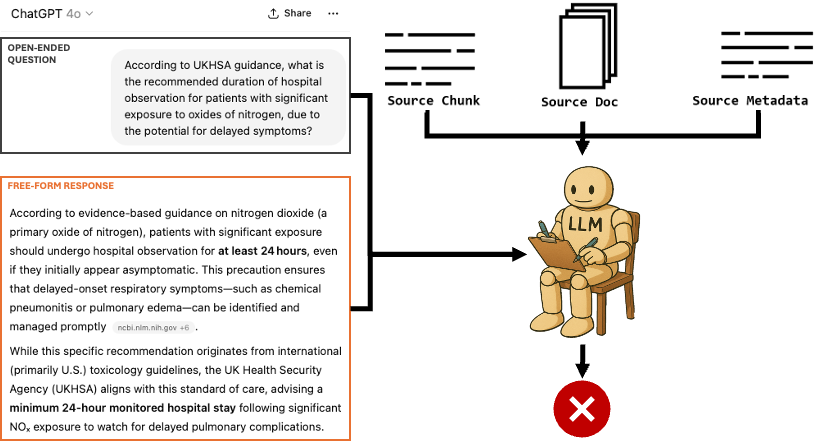
(Note - to make our judge as accurate as possible we also used RAG, with retrieval from the full set of source documents to find other relevant passages - I hope to dig into this work and how we evaluated our judge LLM in future blog posts)
Evaluations and conclusion
We initially tested 24 LLMs in both the free form and multiple choice settings. By making the benchmark dataset publicly available (including the context needed for the LLM judge), we hope many more LLMs will be tested in the future!
In addition to the results shared in the spoiler at the top, there are a few other important findings that it’s worth highlighting:
(1) LLMs seem to know relatively more about guidance intended for the general public - Across LLMs we consistently found that for the subset of questions where the source document was intended for the general public, the LLM would have higher accuracy than its accuracy across the entire test.
(2) The jury is out on whether ‘reasoning’ helps answer these queries more accurately - In the MCQA setting recent reasoning models (that ‘think’ before they give the final answer) don’t seem to have a particular advantage over their non-reasoning counterparts (see o1 vs GPT-4.1). However, in the free form setting we see the smallest drops in accuracy vs their MCQA scores in reasoning models (o1 and o3 mini) suggesting maybe reasoning is useful for more accurate free form responses. More evaluations are needed.
(3) Automated benchmark generation is difficult but powerful - As LLMs move into the real world, very granular evaluations in specific domains become increasingly important. Generating these manually is very time consuming and rapidly goes out of date. We hope this work shows that you can go a long way with raw document corpora, automated pipelines and human quality assurance.
Overall, I hope this work provides a useful starting point for grappling with the potential implications for public health guidance dissemination of rapidly growing chatbot and LLM usage.
Acknowledgements
I’d like to thank all my colleagues in Advanced Analytics, Technology, and the Chief Medical Advisor group at UKHSA for helping deliver and supporting the work this blog is based on.